This blog is intended for architects and developers, who are dealing with the engineering aspects of Cosmos DB, and to decide which service compute option they should go for.
We will start by reviewing the typical challenges that often emerge when using Azure Cosmos DB and when it makes sense to use Cosmos DB in serverless mode.
Typical challenges
In Azure, NoSQL is made available by Azure Cosmos DB, Table Storage, and Redis, to name a few, but the star service remains Cosmos DB.
Many developers tend to rush to Cosmos “for the sake of it” or to “try something different than SQL,” not always with a real business case. They sometimes tend to apply SQL recipes to NoSQL, leading to the following symptoms: slowness and high costs.
Cosmos DB comes with the RU (resource unit) concept, which represents the service effort to accommodate your read and write needs. Every single read or write consumes RUs. As the Cloud consumer, you are charged per RU. So, the more RUs you consume, the more you pay. The most complex piece in Cosmos is to have a good partition key strategy because this has a crucial impact on the consumed RUs as well as on the performance of your system.
Cosmos is based on horizontal scaling, meaning it will use both physical and logical partitions to store your data. Physical partitions are hosted on different servers, while multiple logical partitions can sit on a single server. A single logical partition is always on a single physical server. With this in mind, you can easily imagine that the more servers are involved in a query, the more time it will take and the heavier the task will be to return the data. The problem is that you won’t experience any “bad” symptoms until your data grows significantly. Unfortunately, when the project is already in production, you’ll feel the undesirable side effects of a poor partition key strategy (on performance, costs, or both). It is, therefore, essential to understand the usage model of your Cosmos DB in terms of reads & writes to design it properly. Mind that some initial design flaws might not be recoverable at a later stage.
In Cosmos, the following rules of thumb should be carefully respected:
- Aim at even distribution of data
- Choose a partition key that maximizes the distribution of data across logical partitions
- Avoid cross-partition queries
- Maximize the use of point-reads and single-partition queries.
- Avoid hot partitions
- Hot partitions are often a symptom of a poor partition key strategy, where a maximum of queries always involve the same partition. It causes extra latency and cannot be solved just by increasing the number of allocated RUs, because a single logical/physical partition cannot use more than 10K RUs, for the time being. On top of this, you may hit the max logical partition size limit.
- Anticipate the hard limits of the service
- 10K max RUs/logical/physical partition
- 20GB is the max size of a single logical partition
- 2MB is the max size of a single document (16MB in preview)
These limits vary according to the service consumption mode, which we will see later in this article. Before, let’s make things a little more concrete.
Let us say that you must store book documents. You decide to use an ISBN as the partition key. This design would result in one logical partition per book. The data could not be better distributed. With this simple design, we avoid the following:
- Uneven distribution of data
- Hot partitions
But what about our query needs? If we only need to display the details of a single book at a time, we could always target a single document with a “where id = <id>” query. It would be perfect, but users might want to look for books per country, price range, author, etc. All these queries would lead to cross-partition queries, and in this case, our design would become an impediment, as it is not suited for such queries. From this real example, we can already deduct a different rule of thumb: make sure to know your query patterns and read/write ratios up front. In Cosmos, data redundancy is mainstream. You can accommodate multiple query needs by splitting the same data across containers with different keys. There are also various techniques, such as synthetic and hierarchical keys, but remember that you will never have the perfect design to suit all query needs. So, you’ll have to arbitrate some situations, and the frequency of a given query might be helpful when prioritizing needs.
To make it even more concrete, let’s imagine the following scenario:
You couldn’t find a suitable app to manage your cellar as a wine lover. You decided to create your app and share it with others by publishing it to the different app stores. People can download it and manage their cellar. You designed for potential growth, as you do not know in advance how many users might be interested in using your app. The app responds to the following requirements:
- The home screen should show a dashboard with the number of wines, total cellar value, the average price per wine, and wine count per color.
- The second screen should allow you to add/edit/delete wines. You should also be able to add reviews (possibly more than 1 per wine). Appellations, merchants & wineries should be made available as global pre-defined lists. Users cannot enter free text.
- The third screen should allow you to search for the wine name, the appellation, the country, the merchant, and the winery. Here again, refiners should only list values that exist in the current cellar. You should also be able to search all wines based on the reviews (1 star, two stars, etc.)
The following traditional SQL relational model could efficiently respond to these needs:
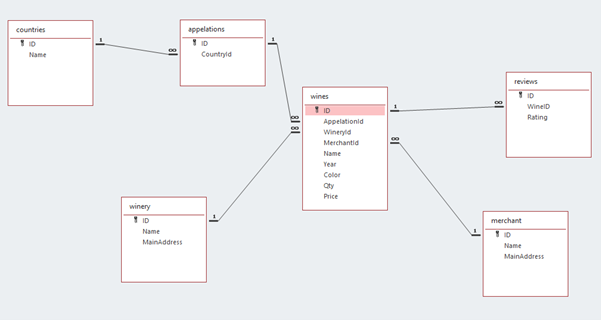
Where you use relational integrity, primary and foreign keys, and where you can play with indexes to optimize speed or let the Azure SQL autotuning do the work for you. A few SQL queries can quickly be done with a few aggregates. You might want to add a view, but nothing complex, no show stopper, and very predictable outcome.
With a relational model, you tend to eliminate redundancy and ensure data integrity. Relational models are based on ACID database engines, which are great but are subject to scalability issues (not suited for Big Data). Of course, for our wine scenario, we will unlikely reach the scalability limits of an ACID-based database engine. Our wine example is not precisely an excellent reason to opt for NoSQL, but it represents what developers want to do in the enterprise. Similarly, ACID-based systems can still be very well accommodated by most enterprise database needs. Probably 99% of the solutions developed today can still be perfectly handled by a traditional database engine.
NoSQL systems, like Cosmos, are articulated around the BASE model, where the primary goal of a BASE system is to make data available at the cost of (immediate) consistency. The primary goal is speed and scale. In an accurate BASE system, you accept eventual consistency (although Cosmos offers STRONG consistency, which is an anti-pattern in itself). In a true BASE system, you don’t care if the number of likes shown on a Facebook or Instagram post is accurate or not as long as it becomes accurate at some point in time. Therefore, NoSQL systems are suited for the massive amount of data (aka Big Data) often incurred by IoT architectures and data platforms. NoSQL stores are often used as an ingestion layer and are part of data platforms. But of course, who can do more, can do less…So, a well-designed Cosmos DB can bring you super-fast applications and infinite scalability, which a traditional database engine could not beat or even equal.
What could be a possible design for our wine scenario? Perhaps this one:
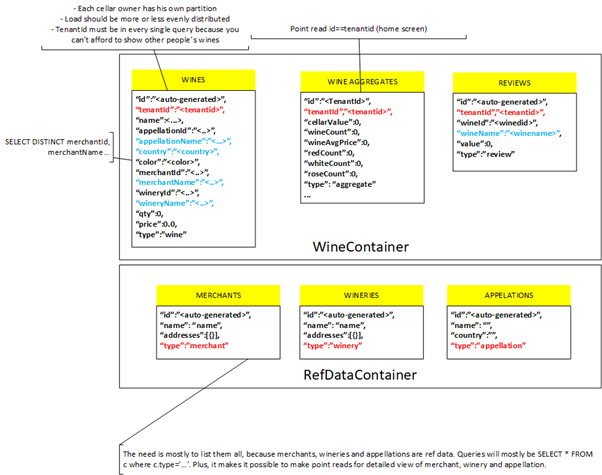
Every Cosmos DB design is subject to debate. In figure 2, some choices were made, such as:
- We have created only two containers. One for the wines and the other for reference data; this choice impacts how we allocate RUs, because RUs can be assigned per container. Wines, WineAggregates, and Reviews share the same partition key (tenantId) and are distinguished using a type attribute.
- tenantId is the partition key of the Wines Indeed, each mobile app user represents a tenant, and you know that each user should only see their wines. You are also confident that data will be distributed because you’ll have as many partitions as users who downloaded your app. You will unlikely never reach the maximum limit of 20GB for a given tenant (cellar), given that you only store text data. Pictures could (and should) be stored in a separate Storage Account. We have added some attributes, such as merchant name, color, etc., to respond to requirement #3
- You create a dedicated WineAggregates container to accommodate the query needs of requirement #1. This document will be updated by leveraging Cosmos DB post-update triggers. Because this view is required in the home screen of our app, we will use a point-read operation, meaning the fastest and cheapest Cosmos DB operation.
- The RefDataContainer enables requirement #2, which is the availability of global (not tenant-related) lists for merchants, etc.
You could probably develop five variants of this design for the same need. This simple example shows how complex it is to design a Cosmos DB. It also shows the importance of knowing the query needs upfront. Because the learning curve is rather steep, you should choose your compute mode carefully.
Cosmos comes with two compute modes:
- Pre-provisioned throughput, with or without autoscaling
- Serverless
The benefit of pre-provisioned throughput is that the compute is pre-allocated to your instance. It is “waiting” for you to consume it. Therefore, you do not experience a “cold start” or a shortage of resources, provided you remain within your defined boundaries. On the field, you often see that teams start small with reasonable pre-provisioned throughput. Still, they increase the throughput over time to compensate for a poor design until it becomes almost unpayable (or unusable).
The benefit of the serverless mode is the same as with every serverless offering: you only pay for what you consume. The serverless method is, in theory, preferred for workloads that idle from time to time and do not require predictable latency. Typically, jobs and asynchronous operations are ideal. A nightly scheduled data synchronization job is the perfect use case. However, even if your scenario differs from the above examples, it also makes sense to use the serverless mode for the following use cases:
- In lower environments (dev/test) where the higher latency, compared to provisioned throughput, is not predominantly an issue and where an idle period is mainstream
- For proof-of-concepts
- While you are still learning the usage patterns of your application and their impacts on costs, you can perform a cost analysis on the serverless Cosmos DB to better calibrate the provisioned throughput you will end up with in production. Moreover, the serverless tier has lower service limits, so you might hit them earlier and possibly fix design issues before reaching production.
Streamlining Azure Cosmos DB management with Cerebrata
- Manage multiple Cosmos DB accounts targeting different APIs (SQL, Table, Gremlin & Mongo) – all in one place.
- Get responsive charts to view the size and number of the documents stored in each logical partition in Cosmos DB SQL API.
- Build an initial query and save them using Cerebrata’s Query Manager to retrieve business-critical data from Cosmos DB Accounts.
- Effortlessly transfer data from Storage Table to Cosmos DB SQ API containers.
- Easy-to-use Query Builder for building ODATA queries without the requirement of syntax
- Easily set up and modify all possible throughput modes – Serverless, Auto Scale & Provisioned.
- Download data from the Cosmos DB account and store them in JSON format for offline purposes.
Apart from Azure Cosmos DB Management, Cerebrata also offers unique features for other Azure services, such as Service Bus, Event Grid, Storage Account, Redis Cache, etc.
Managing multiple Azure services effectively often requires switching between Service Bus Explorer, Cosmos DB Explorer, Storage Explorer, or other management tools. This drawback can be eliminated using Cerebrata (a cross-platform desktop tool), which provides management for various Azure services through one single interface. Try it out yourself by signing up for a 15-day free trial!
Conclusion
Cosmos DB requires a lot of thinking and a lot of precautions before launching a data model in production. You must keep in mind the hard limits and keep costs under control. The serverless offering can help you in that journey. I strongly encourage any team learning Cosmos to envision serverless first, learn from it, and then switch to provisioned throughput unless your use case is ideally in line with the serverless offering.