Introduction
Indexing is an important feature in all storage management systems. Indexes are used to quickly locate data without having to search every row in a database container every time a database container is accessed. With proper indexing, data can be retrieved faster. In this article we will learn about indexes in Cosmos DB and how Cosmos DB indexes can be managed in managed efficiently using Cerebrata.
Default Indexing in Cosmos DB
In Azure Cosmos DB, indexes can be defined for the containers in the databases available in Azure Cosmos DB accounts. Whenever a new container is created, indexes are created for every property in every item. It also creates range indexes for the datatypes, string, and number. So, we need not consider about creating the indexes and query performance when we create a container.
This default indexing behavior of a Cosmos container can be modified by setting the indexing mode and include/exclude property paths.
Indexing modes
Two different indexing modes are provided by Azure Cosmos DB.
- Consistent
- None
Consistent
In consistent indexing mode, the indexes are updated synchronously whenever an item is either added, updated, or deleted. The consistency of the read queries here will be the consistency configured for the Azure Cosmos DB account.
None
Indexing is not enabled for the container in this indexing mode. This indexing mode can be useful when the container stores the data in the form of Key Values pairs. This will be useful when we are going to perform any bulk insert, update or delete operations. The bulk operations can be completed much faster when the indexing is disabled on the container. This can also be used when there is no need for any secondary indexes. We can enable the indexing when the bulk operations are completed.
Lazy indexing mode
In this mode, the indexes will not be updated immediately. The indexes will be updated when the engine is not doing any other work which will result in inconsistent or incomplete query results. Lazy indexing mode cannot be selected for newly created containers. Lazy indexing mode can be selected by contacting Azure support. This is not supported in Azure Cosmos DB accounts in Serverless mode.
Time-To-Live (TTL) and Indexing mode
If we want to use the Time-To-Live (TTL) feature for Cosmos containers, we must set the indexing mode to consistent. i.e., We cannot activate the TTL on a container when the indexing mode is set to none.
Points to be considered while creating indexes
In Azure Cosmos DB, not only you’re charged for provisioned/consumed throughput but also for the data stored. The total size of the data stored is calculated based on the combination of the size of actual data stored and the that of the indexes. The index size depends on the indexing policy of the container. For example, when the indexes are created for all the properties the index size will be large. So, we must carefully specify the include/exclude property path while defining the indexing policy as it will have cost implications.
When there is a physical partition split, there will be a temporary increase in the index size. The index space will be released once the physical partitioning is completed.
Include/Exclude Property Paths
Include Property Path:
The term Include Property Path refers to the path of field in the JSON that must be included for indexing. The value in the provided path will be stored as indexes.
Exclude Property Path:
The term Exclude Property Path refers to the path of field in the JSON that must be excluded from indexing. The value in the provided path will not be stored as indexes.
The indexing policy can be customized by specifying the include and exclude property paths. The latency and the RU charge for the write operation Azure cosmos containers can be reduced by optimizing the property paths that are indexed.
Include/exclude Strategy
- The root path /* must be included in any of the indexing policy as either an included or an excluded path.
- The root path must be included to selectively exclude paths that do not need to be indexed. This will be useful when new properties will be added progressively to the data model and the newly added properties will be indexed automatically.
- The root path must be excluded to selectively include paths that need to be indexed. This can be mainly used when the data model is defined.
- The system property _etag is excluded from indexing by default, if etag is not included in the include property path.
- The system properties id and _ts are automatically indexed when the indexing mode is set to consistent.
When including and excluding paths, you may encounter the following attributes:
- Kind: kind can be either range or hash. Hash index can be used only for equality filters. Range index functionality supports all the functionality of hash indexes. It is also efficient for sorting, range filters and system functions. Range index is the most recommended indexing kind.
- Precision: Precision is a number defined at the index level for included paths. -1 can be used to set maximum precision. Setting this value to -1 is mostly recommended.
- Data Type: The datatype can be either String or Number. This indicates the types of JSON properties which will be indexed.
Precedence of Include/Exclude Property Paths
When there is a conflict between the include and exclude property path, the more precise path has higher precedence than the less precise path.
Let us consider the following example.
Include Property Path: /location/address/zipcode/*
Exclude Property Path: /location/address/*
In this case according to the exclude property path the address field must be excluded from indexing. But, according to the include property path, the zipcode field within address must be included for indexing. Since the include property path is more precise than the exclude property path, all the properties in address field will be excluded from indexing except the zip code field.
Below are some of the rules that must be followed while specifying the include/exclude property paths.
- The root path /* must be included either in the include/exclude property path.
- Deeper paths are more precise than the narrower paths. i.e., /a/b/c/* is more precise than /a/b/*.
- /a/? is more precise than /a/*. So /a/? will take higher precedence than /a/*.
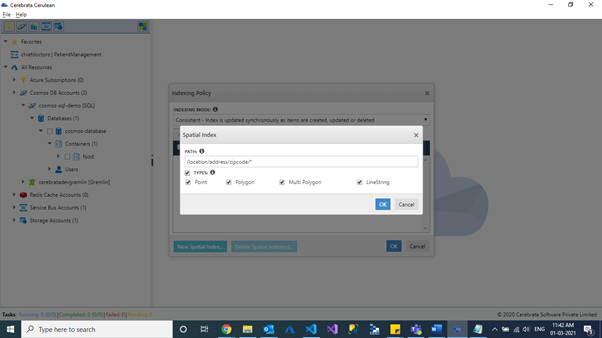
Spatial Indexes
Index type to be applied to that path must be defined, when defining a spatial path in the indexing policy. Following are the types for spatial indexes.
- Point
- Polygon
- MultiPolygon
- LineString
Spatial indexes will not be created by default in the Azure Cosmos DB. For using spatial SQL built-in functions, spatial index must be created on the required properties.
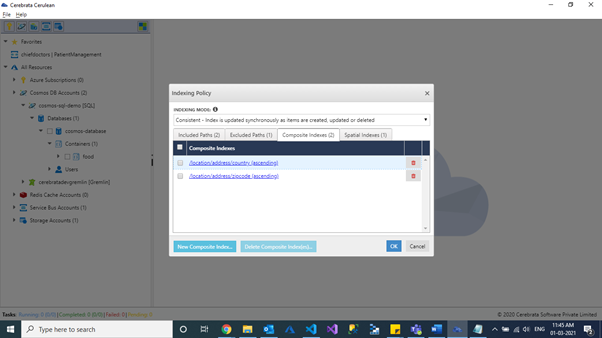
Composite indexes
Queries having an ORDER BY clause with two or more properties require a composite index. A composite index can be defined to improve the performance of many equality and range queries. There are no composite indexes are defined by default.
Root path /* cannot be used while creating a composite index. Every composite path will have an implicit /? at the end of the path that need not be specified. Composite paths lead to a scalar value and this is the value included in the composite index.
Following must be specified by creating a composite index:
- Two or more property paths. The sequence in which property paths are defined matters.
- The order (ascending or descending).
Cerebrata for Better management of Indexing Policy in Azure Cosmos DB
Cerebrata provides a much better experience for managing indexing policies on a container. In this section we will talk about how you can define and manage indexing policies for a container through “Data Explorer” feature in Azure Portal as well as in Cerebrata.
Create Container
When we create a container in an Azure Cosmos Account database through Azure portal, we will be able to either enable or disable the indexing.
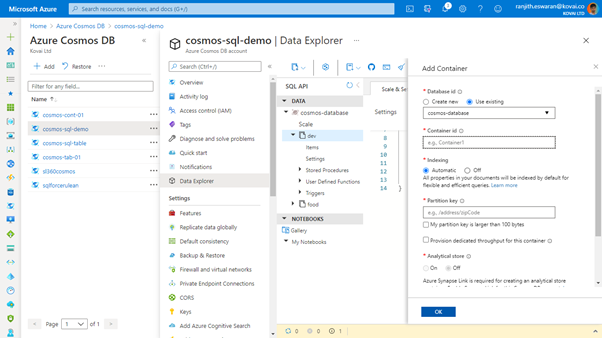
It is not possible to specify the include property paths, exclude property paths, composite indexes and spatial indexes while creating the container.
However when we create a container using Cerebrata we can specify the following.
- Indexing mode
- Include Property paths
- Exclude Property paths
- Composite indexes
- Spatial indexes
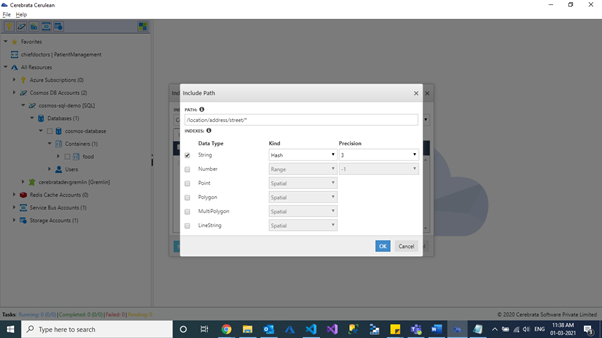
We can specify the path, datatype, kind and precision of the include property path.
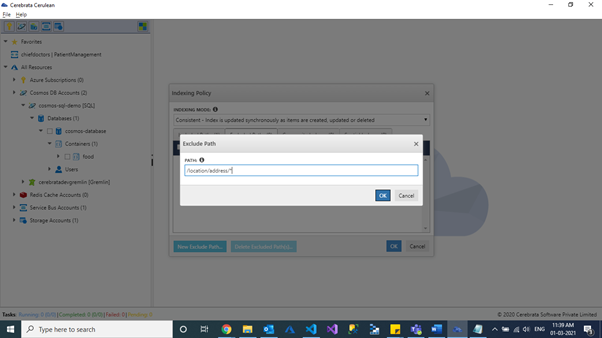
We can specify the exclude property path.
We can provide the composite index paths.
We can create spatial index during container creation.
Updating Indexing Policy
In Azure Portal, it is possible to view the indexing policy including include property paths, exclude property paths, composite indexes and spatial indexes can be viewed and edited as a JSON configuration.
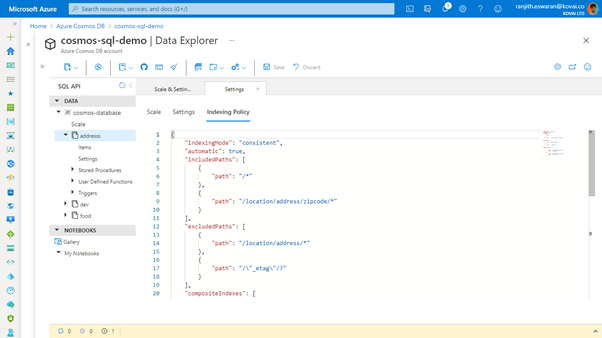
Essentially when working in Azure Portal, you must be aware of how to structure the indexing policy. You should know the parameters needed to define included/excluded paths, composite indexes etc.
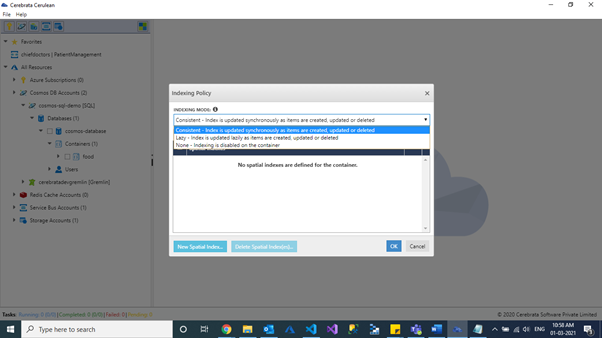
In Cerebrata, we can view the indexing policy in a clean user interface and edit them in a much simple manner.
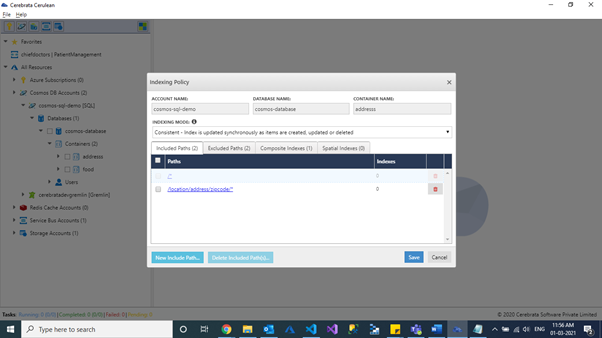
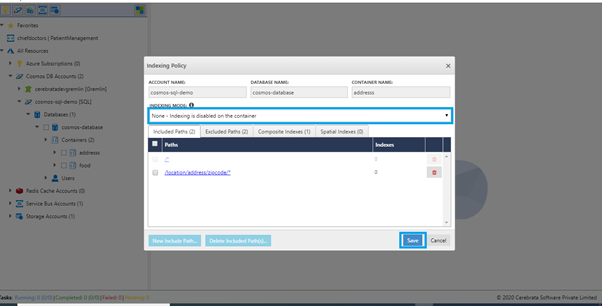
Changing the Indexing Mode
Cerebrata also allows to update the indexing mode of a container to consistent indexing or none in a simple and easier approach.
Azure Cosmos DB management – Perform CRUD operations on databases, containers, items and advanced operations like sophisticated query manager, bulk operations, transfers with Cerebrata.
Conclusion
In this article we saw about the indexing policy in Azure Cosmos DB and we also saw how to manage the indexing policies efficiently using Cerebrata. In addition to the Azure Cosmos DB, Cerebrata also supports other Azure services like Azure storage, Azure Cognitive Search, Service Bus, Redis Cache, etc. Cerebrata helps you to manage these Azure services in a simple and user-friendly manner.
If you wish to experience Cerebreta, try our 15 days free trial.